
The paradox has two sides
In January 2025, Satya Nadella posted a link to the Wikipedia article on Jevons paradox. The timing was deliberate. DeepSeek had just released a model that made frontier AI cheaper overnight, and the market was wobbling. Nadella’s one-line commentary: “Jevons paradox strikes again! As AI gets more efficient and accessible, we will see its use skyrocket, turning it into a commodity we just can’t get enough of.”
He was right, at least on the aggregates. A year later, the data is lopsided in his favor. Software-engineering openings at tech companies are up roughly 30% year-to-date in 2026 per TrueUp’s aggregator (tracking ~9,000 tech companies), even as broader tech postings remain well below their 2022 peak. PwC’s 2025 Global AI Jobs Barometer reports that productivity growth in AI-exposed industries has nearly quadrupled, from 7% cumulative over 2018–2022 to 27% cumulative over 2018–2024. Revenue per employee in AI-exposed industries grew roughly three times faster than in least-exposed industries over the same window. The total labor pie is growing, and it’s growing fastest exactly where people predicted it would shrink.
This is the take that crushed on my LinkedIn last month. Cheaper software means more software. More software means more work. Nothing about it is false.
But pointing at the total and calling it good news hides what the totals are actually made of.
Quick detour: what Jevons actually said
In 1865, an economist named William Stanley Jevons noticed something counterintuitive about steam engines. They were getting dramatically more efficient. Each ton of coal produced more work than the year before. Everyone expected coal consumption to drop. Efficiency should save fuel.
It didn’t. Coal consumption went up.
The reason was straightforward once Jevons explained it. Cheaper energy opened uses that weren’t economical before. Factories expanded. New industries started. Railroads extended. The total demand for coal grew faster than efficiency reduced it.
That’s the paradox. When you make something more efficient, you don’t necessarily use less of it. You often use more of it, because cheaper access unlocks demand that was previously priced out.
It’s been applied to electricity, fuel economy, bandwidth, and now AI. The logic is the same every time: when the cost of a thing drops, demand for that thing tends to grow faster than the savings. The pie expands.
The part everyone quotes
If you read only the top-line numbers, Jevons looks airtight.
AI-related roles are up across the board, despite two years of tech-sector layoffs. PwC’s 2025 Barometer shows the AI wage premium doubling in a single year, from 25% in 2023 to 56% in 2024, meaning roles requiring AI skills now pay 56% more than otherwise comparable roles that don’t. The same barometer shows AI-exposed industries (not occupations) saw 16.7% wage growth over 2018–2024, revenue per employee growing three times faster than in least-exposed industries, and productivity growth nearly quadrupling as noted above. (One caveat worth naming: PwC classifies industries as “AI-exposed” via a task-composition proxy, not observed AI use. These are strong correlations, not causally identified effects.) Total coal consumption went up when steam engines got efficient, and total demand for software is doing the same thing.
The 2023 panic about AI replacing coders hasn’t played out, at least at the aggregate level. Claude Code ships code. Engineers ship more code. Companies ship more software. The market absorbs more software than it did last year. Nothing about the shape of the industry suggests contraction.
Mr Phil Games wrote a piece on exactly this called Jevons’ Paradox and AI: Why It Means More Developers, Not Fewer. The argument is straightforward. Software was never a fixed pie. The cost of writing it dropped. The volume being written went up. The ceiling on useful software is much higher than we ever acknowledged, because the constraint was always the cost of building, not the demand for it.
This is correct. I’ve said it myself, in almost these exact words.
The trouble is that the same dataset tells a different story if you read it from the bottom up.
The part nobody prices in
The totals are growing. The composition isn’t. Three independent datasets tell the same story. Per Indeed Hiring Lab, entry-level tech postings in February 2025 were off 34% vs February 2020 while senior postings were off only 19%, and the share of tech postings requiring 5+ years of experience rose from 37% to 42% between Q2 2022 and Q2 2025. The Stanford Digital Economy Lab’s ‘Canaries in the Coal Mine’ paper (Brynjolfsson, Chandar & Chen, November 2025 revision, using ADP payroll data through September 2025) finds a 13% relative employment decline for workers aged 22–25 in the most AI-exposed occupations, with 22–25-year-old software developers specifically down roughly 20% from their late-2022 peak. The 35–49 cohort moved the other way: up about 9% over the same window. The Dallas Fed replicated the age-AI-exposure pattern in CPS data in January 2026. Same industry. Opposite directions.

That 56% wage premium for AI skills? It doubled in a single year. A 25-point gap became a 56-point gap. Two years before that, the category didn’t really exist. The financial reward for AI fluency isn’t leveling off. It’s accelerating.
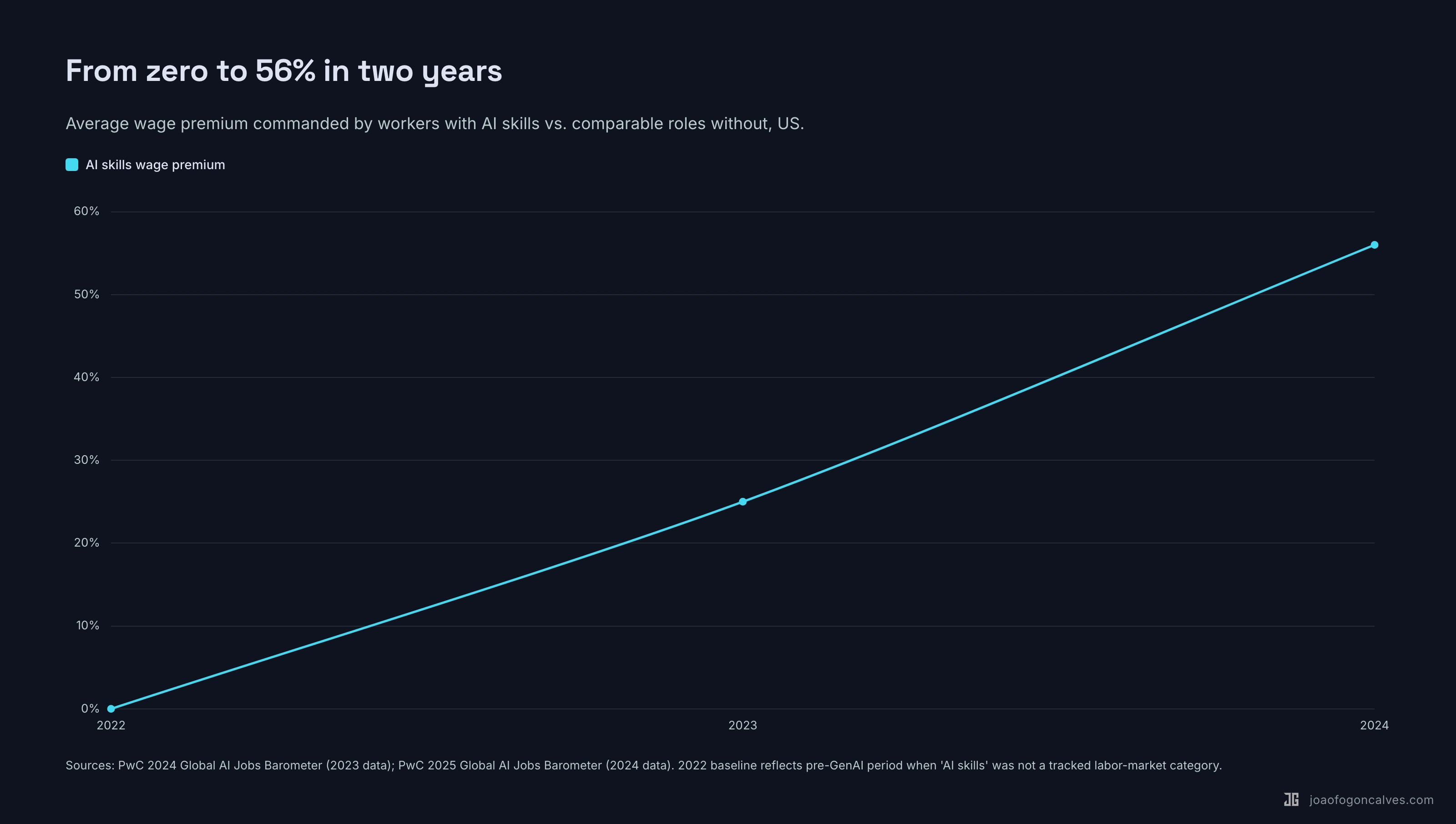
PwC’s data, read carefully, says the same thing in a less comfortable way. AI-exposed roles are growing revenue per employee 3x faster than non-exposed roles. That’s a widening gap between the boats that move and the boats that don’t.
The Anthropic Economic Index from March 2026 adds a quieter datapoint. Roughly 49% of O*NET-defined jobs have had at least a quarter of their constituent tasks appear in Claude conversations at least once, with computer and math work the largest category. Anthropic’s separate “effective coverage” measure, which weights by success rate, is materially lower; the 49% is a high-water mark, not a measure of AI actually doing the job. The gap underneath is where the distribution is separating. The Stack Overflow 2025 Developer Survey shows the same gap from a different angle: developer AI usage hit 84% (up 14 points year over year), but trust in AI output landed at just 33–54% depending on task type. Adoption is wide. Mastery is narrow.
The pie is growing. The line at the door is getting longer.
Why both things are true
Both readings are correct. They aren’t describing different economies. They’re describing different halves of the same one.
Jevons says: when a thing gets cheaper, more of it gets made. Software gets cheaper, more software gets made, more people get hired to make it. That’s the first-order effect and it’s real.
The second-order effect is the one nobody quotes. When the marginal cost of adequate output drops to near zero, the new demand skips past adequate entirely and lands on work that requires something adequate can’t deliver. Leverage. Judgment. Taste. The ability to orchestrate five agents toward one outcome. The ability to decide what’s worth building in the first place.
The sharper way to put it: the person doing adequate work at adequate speed is in trouble, because adequate is now free.
The middle of the skill distribution isn’t being squeezed by less work. It’s being squeezed by work it can’t do. Jevons creates the demand. Adequate-is-free determines who that demand reaches.
The shape of that squeeze is already visible in team-level telemetry. Faros AI’s 2026 report on roughly 22,000 engineers using AI-assisted tools found per-developer pull requests merged up 98% and epics per developer up 66%, while team-level PR review time jumped 441% and incidents per pull request jumped 243%. The bottleneck moved off typing. It moved onto review, triage, and judgment. Jevons delivered the volume; the volume is what needs to be judged.
Both things are true. They just measure different parts of the same shift.
Who gets the new jobs
There are two doors. Most people who will thrive in the next five years walk through both. Almost everyone who doesn’t will be locked out by one.
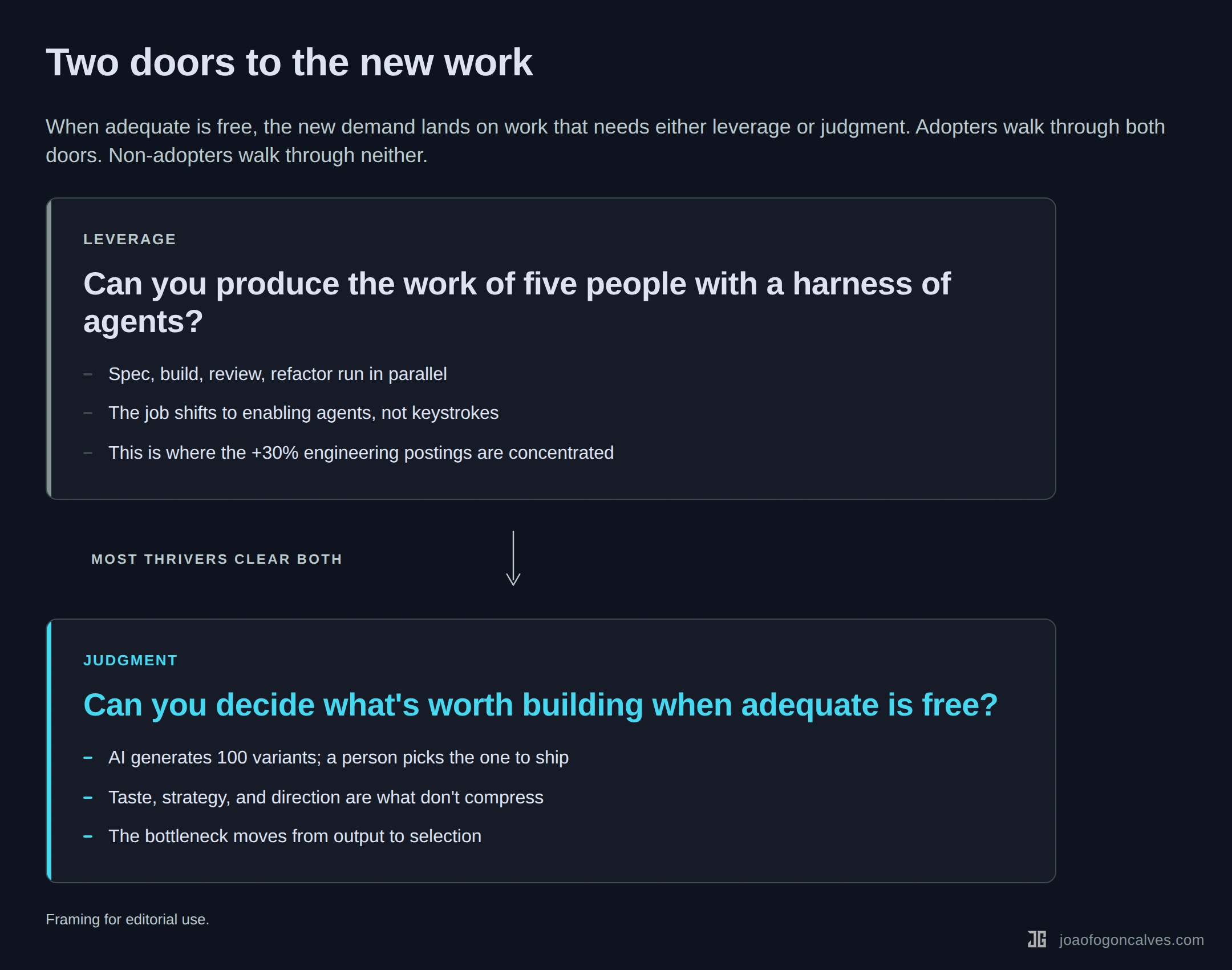
The first door is leverage. Can you produce the work of five people with a harness of agents? A senior backend engineer I work with ships three features in the time her team used to ship one, because she runs Claude agents in parallel on the review, the migration, and the documentation pass. Her day-to-day isn’t typing. It’s queuing, checking, correcting. The engineers whose postings are up are the ones building that kind of harness on themselves.
Leverage isn’t free on day one, and it isn’t automatic. The Harvard/BCG/Wharton “Jagged Frontier” study found that consultants using GPT-4 on tasks inside the model’s capability frontier produced roughly 40% higher quality output and finished about 25% faster. The same consultants on tasks just outside that frontier performed measurably worse than a control group without AI. Leverage looks like picking the right tasks to delegate, not delegating everything. METR’s 2025 study of sixteen experienced open-source developers working on their own repos found something uncomfortable along the same lines: when early-2025 AI coding tools were allowed, those devs took 19% longer to complete real tasks than when they weren’t, with the 95% confidence interval for the slowdown landing between +2% and +39%. They felt 20% faster. They were 19% slower. Brownfield code on a repo you already know is the hardest test for AI, exactly the case where the frontier is narrowest. METR’s own February 2026 update, titled “We are Changing our Developer Productivity Experiment Design,” reports preliminary signs of speedup with newer tools (returning-cohort devs −18%, newly-recruited −4%) but labels those findings “only very weak evidence” and is redesigning the study around severe selection effects. The 19%-slower headline for early-2025 tools still stands. Whether it generalizes to current tools is an open empirical question. The Stanford AI Index 2026, released earlier this month, lands in roughly the same place: controlled studies show 14–26% productivity gains for software engineering with current-generation AI, but gains turn “smaller or negative for judgment-heavy tasks.” Both readings agree on the shape. The tool gives you leverage where the frontier is broad and costs you time where it isn’t. The leverage door doesn’t open by installing Copilot. It opens after the dip, for the people who pushed through the first painful months when every prompt felt slower than just typing the code. Most people never clear the dip. The ones who do are the ones getting paid 56% more.
The second door is judgment. When adequate code is free, the bottleneck moves to deciding what to build, what to kill, what good looks like. Product teams that used to draft one spec a week now see ten variants before lunch. The PM’s value is no longer writing the spec. It’s triaging the ten. Most PMs don’t yet have the muscle for that kind of picking. The ones who do are about to get paid for it.
Adopters get both doors. Non-adopters get neither. The people in the middle, doing careful, correct, adequate work at a pace that used to be valuable, are discovering that neither door opens for them anymore.
But isn’t this just reskilling panic?
The skeptical reader’s objection writes itself. Every general-purpose technology produced this same narrative. Electricity was going to end factory labor. The PC was going to kill middle management. The internet was going to kill retail. The labor share didn’t collapse. People upskilled. New roles appeared. The economy absorbed the change.
It’s a fair objection. It may still be right.
But two things make this wave harder to pattern-match to the prior ones.
First, the adequate-is-free dynamic is categorically different. In past waves, a technology made a narrow skill obsolete: a specific typewriting task, a specific filing job. The worker’s broader capability still had a market. AI collapses “producing adequate output at adequate speed” as a general category. That’s a much wider zone of the distribution to reroute.
Second, the pipeline problem. If the first rung of engineering, writing mediocre code under supervision for four years, is the rung vanishing, how does the industry make senior engineers in 2030? The seniors using AI for leverage today didn’t train under AI supervision. The next cohort will. What they turn into is not obvious, and nobody is running the experiment deliberately.
The people betting on historical adaptation aren’t wrong. They’re betting on a pattern that may hold. But prior adaptation windows were measured in decades, not quarters. The best-studied general-purpose-technology parallel, the personal computer, famously took five to fifteen years to show up in aggregate productivity statistics at all. Paul David’s 1990 paper “The Dynamo and the Computer” named this the Solow productivity paradox, and Brynjolfsson and Hitt’s 2003 follow-up on IT and firm-level productivity showed the full diffusion curve playing out over a decade and a half. AI diffusion is running on a different clock. The Anthropic Economic Index alone recorded task coverage of O*NET jobs jumping from 36% in February 2025 to 49% in February 2026. Thirteen points in ten months. If adaptation is happening, it’s happening at a pace that leaves most of the workforce behind it.

But doesn’t AI code rot?
The second predictable objection, and a harder one, is about quality. If adequate is free, the argument goes, what actually shows up in the repos isn’t software. It’s a pile of plausible-looking code with a time bomb on it. The 10× output has a 10× maintenance tail. The wage premium is paying for a mess the industry will spend a decade cleaning up.
The numbers behind the critique are not nothing. GitClear’s 2025 research on millions of pull requests found copy-pasted code now exceeds refactored code for the first time since they started measuring, code clones grew roughly 4× in the two years after AI coding assistants went mainstream, and bugs-per-developer ticked up 54% on high-AI teams. Scientific American, summarizing Berkeley Haas research from early 2026, found AI-assisted developers shipping more tasks per week but also logging longer hours and more out-of-hours fixes. The METR numbers above are part of the same picture: the feeling of speed outruns the measure of speed by a wide margin, and nobody notices until they audit their own calendar.

Name these critiques properly. The first is the technical debt bomb: AI produces more surface area to break. The second is the productivity illusion: we are measurably slower at the exact moment we feel fastest. The third is the senior pipeline collapse: if the junior rung is vanishing (entry-level tech postings down 34% from 2020), where do the seniors of 2032 come from?
Every one of these is real. None of them invalidates the Jevons reading.
The maintenance tail on an adequate-code flood is not a reason to expect fewer jobs. It’s a reason to expect different jobs, concentrated in exactly the slots described above. More code written by agents means more code to review, more conflicting patterns to reconcile, more decisions about what to keep and what to delete, more senior judgment about which auto-generated migration will explode on Monday and which one is safe. The quality debt is the thesis stated from the other side of the ledger. Adequate output is cheap. Editing, triaging, orchestrating, and deciding are what everyone is about to discover they actually needed seniors for in the first place.
The senior pipeline argument is the one worth sitting with the longest. It’s the only one that doesn’t resolve neatly. If the junior rung of the ladder was always write mediocre code under supervision for four years and absorb taste by osmosis, and the junior rung is vanishing, it is genuinely unclear how the next cohort of seniors gets made. The optimistic answer — juniors skip straight to orchestrating agents and pick up taste faster because the iteration loop is tighter — is plausible and being run as a live experiment by approximately zero organizations on purpose. The pessimistic answer — the industry is eating its seed corn and won’t know it until 2030 — is also plausible. Nobody has the data yet.
What we can say: the short-run effect is unambiguously pro-senior, and that effect gets stronger the worse the quality of AI-generated code actually is. The critics and I are looking at the same data. We just draw opposite arrows from it. They say the flood of adequate code is a bug in the Jevons argument. I’d say it’s the engine.
Why this is hard to hear
The obvious response to all this is: fine, tell people to adopt. Run the training. Hand out Copilot licenses. Mandate the tools.
It doesn’t work that way. I wrote about this in an earlier piece, Pain Gets You In The Door. Curiosity Builds Everything Else. The research on AI adoption is consistent and uncomfortable. Mandate-driven adoption crowds out intrinsic motivation. The people who adopt because they’re told to don’t build the deep fluency that adopters-by-curiosity do. Luo, Zhou & Cui (2026) in Education and Information Technologies find perceived enjoyment (the intrinsic-motivation variable in a standard UTAUT model) the strongest predictor of generative AI adoption, ahead of performance expectancy, effort expectancy, and facilitating conditions. Lai, Cheung & Chan (2023) in Computers & Education: AI found the same pattern against Technology Acceptance Model variables. Across the literature, intrinsic motivation is among the strongest predictors of creative and frequent use. Ahead of training. Ahead of org support.
The pattern isn’t that mandates never work. IBM’s AskHR reportedly automated “a couple hundred” HR roles while IBM’s net headcount grew elsewhere (Arvind Krishna, WSJ, May 2025). The failure mode is narrower: mandates without curiosity tend to produce shallow users, not the fluent orchestrators leverage rewards.
The workers most exposed to the adequate-is-free shift are also the ones most likely to get the framing that guarantees they won’t close the gap. “Just use AI.” “Upskill.” “Get with the program.” These are the phrases of the adoption pattern that doesn’t stick.
If you’re waiting for your company to pull you through this shift, your company is statistically the worst-positioned actor to do it.
The door is still open
Jevons is real. AI will create more jobs. That was never the question.
The question was who gets to do them.
The top-line data says the pie is growing. The bottom-line data says the growth is concentrated above adequate. Both halves of the story are true. Nadella was right about Jevons. The adequate-is-free framing is the other half. The engineers shipping 10x with Claude Code and the designers watching their adequate-tier competitors get priced to nothing are living in the same economy, describing the same shift from different sides of the door.
If you’re already through both doors, leverage and judgment, the next five years are the best window you’ll see in your career.
If you’re not through yet, the move isn’t to wait for your company to train you. It’s to build leverage on your own time this week. Pick one task in your job that today takes you four hours. Rewire it so an agent does the first pass and you do the judgment pass. Ship it. Do the same thing next week with a different task.
The door is still open. It’s just getting stricter every quarter.
Sources & further reading
Jevons & aggregate demand
- PwC 2025 Global AI Jobs Barometer - wage premium, productivity growth, revenue-per-employee ratios at industry level
- PwC press release: AI linked to fourfold productivity growth - the 7% → 27% productivity-growth-rate figure
- Anthropic Economic Index, March 2026 - O*NET task coverage across occupations (49% of jobs at ≥25% tasks)
- Stanford AI Index 2026 - 14–26% productivity gains for software engineering with current-generation AI
- Mr Phil Games, “Jevons’ Paradox and AI” - a clean statement of the optimistic case
- Satya Nadella on Jevons, January 2025 - the post that started the cycle
Labor composition
- Brynjolfsson, Chandar & Chen, “Canaries in the Coal Mine” (Stanford Digital Economy Lab, Nov 2025 revision) - 13% relative employment decline for workers 22–25 in most AI-exposed occupations (ADP payroll data through Sept 2025)
- Indeed Hiring Lab: experience requirements have tightened - 5+ years experience requirement rose 37% → 42% Q2 2022 to Q2 2025
- Stack Overflow 2025 Developer Survey (AI section) - 84% adoption, 33–54% trust
- TrueUp via metaintro: engineering listings up ~30% - narrow tech-aggregator scope (~9,000 tech companies)
Productivity & quality evidence
- METR, July 2025 - RCT on sixteen experienced OSS developers, 19% slowdown, 95% CI +2% to +39%
- METR, February 2026 experiment redesign - preliminary speedup labeled “only very weak evidence” with severe selection effects
- Faros AI 2026 telemetry report - 22,000 engineers: PRs merged +98%, review time +441%, incidents per PR +243%
- GitClear 2025 code quality research - 4× code clone growth, +54% bugs per developer on high-AI teams
- Scientific American, March 2026 - Berkeley Haas on longer hours for AI adopters
- Dell’Acqua et al., “Navigating the Jagged Frontier” - Harvard/BCG/Wharton GPT-4 consulting study
Historical parallel
- Paul David (1990), “The Dynamo and the Computer: An Historical Perspective on the Modern Productivity Paradox,” AEA Papers and Proceedings - origin of the Solow productivity paradox framing
- Brynjolfsson & Hitt (2003), “Computing Productivity: Firm-Level Evidence,” Review of Economics and Statistics - 5–15 year IT productivity diffusion lag
Adoption psychology
- Luo, Zhou & Cui (2026), Education and Information Technologies - perceived enjoyment strongest UTAUT predictor of generative AI adoption
- Lai, Cheung & Chan (2023), Computers & Education: AI - intrinsic motivation vs TAM variables, same pattern