Posts
281 postsShort-form notes on AI, engineering, and the work in flight.
Every substantive change in our repos ends with the same request to the model: update the docs this change just made sta
That's the entire system. No documentation sprints, no wiki cleanup quarter. Docs always rotted for the same reason: the update was a separate task, assigned to a human who had already moved on. The knowledge was freshest at the exact moment nobody...

Self-hosted infrastructure tools don't lose to AWS or Vercel on features. They lose on trust.
Nobody evaluates a deploy tool by asking if it can run a container. They ask what happens when someone leaves the company, whether an audit log can leave the building, and whether a bad rollout gets undone before anyone notices. Alerts either fire...
Fable and Mythos are the same model.
Same weights, same benchmarks. The only difference is a classifier layer sitting in front. Fable routes sensitive queries away. Mythos lets them through, for a vetted list of security and bio researchers. One brain. Two doors. The guardrail is the...
Verifying what a coding agent built is now harder than building it. A new paper from the Qwen team says why: intent can'
The paper is about training. But you hit the same gap every time you prompt. The model has the capability. It's being asked to infer an intent you kept in your head, then graded against your private copy of it. And evaluating intent is hard for the...

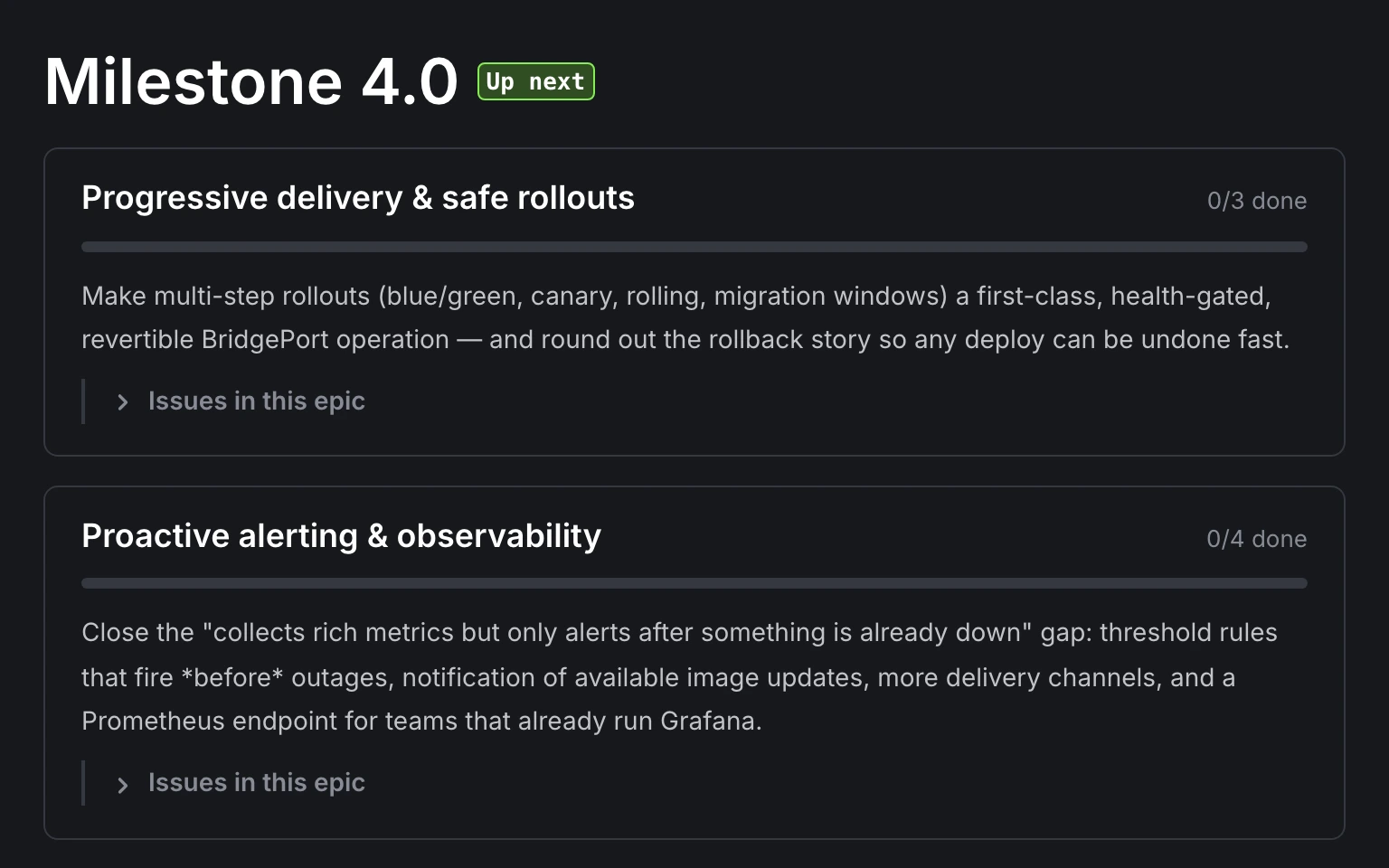
BridgePort 3.0 is out, with two new ways to drive it.
A Terraform provider, so your environments, servers, secrets, and services live in version control and terraform plan shows drift before it bites. And an MCP server, so you can operate it from an AI agent in your editor. The MCP server is the...

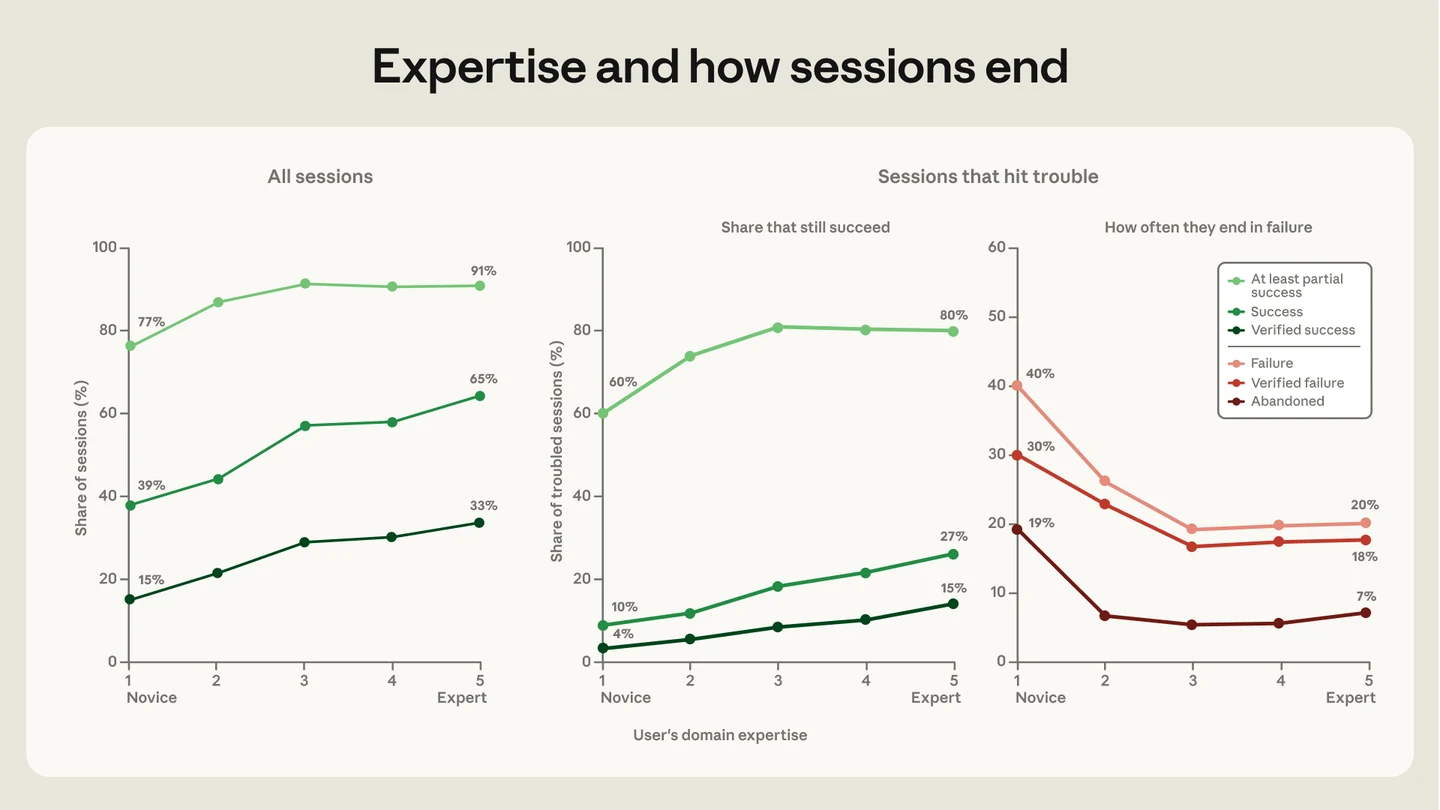
The story everyone wanted was that cheap AI flattens the skill curve. Anybody can ship now, the gap closes, expertise st
Anthropic just put numbers on it. 400,000 Claude Code sessions, 235,000 people. Novices reach verified success 15% of the time. Intermediate and expert users, 28 to 33%. The tool got cheaper. The gap held. The research is titled "persistent returns...
You can't hire someone who already holds your team's judgment. Nobody has it.
The incidents that built it happened in your production, against your data, with your customers finding the failure modes only your product has. The best engineer on the market shows up with deep judgment about systems that aren't yours. Worth a...

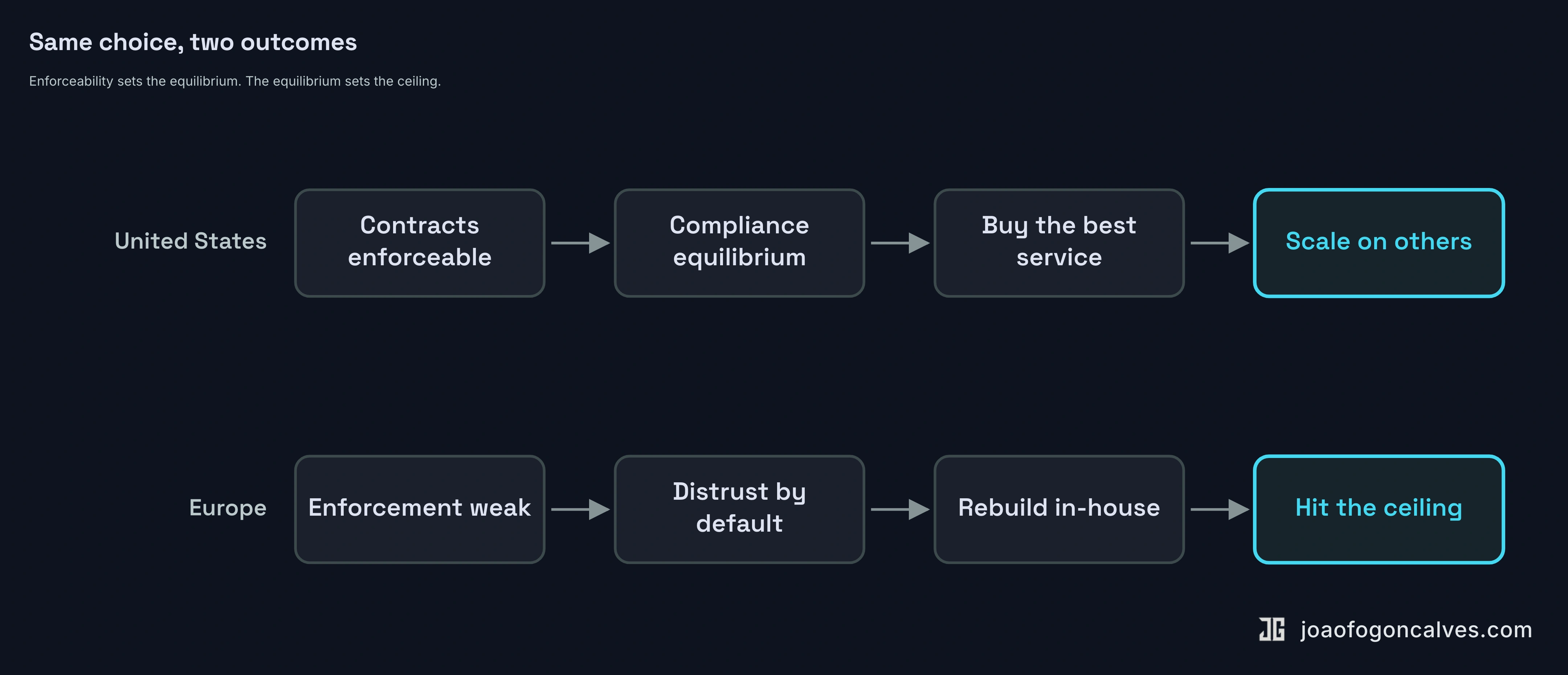
European companies rebuild software that already exists. Constantly. Give an American company the same choice and it buy
The difference comes down to one question: if a vendor breaks the deal, can you make it hurt? In the US, yes, and fast. That one fact changes the math. It produces what game theory calls a Nash equilibrium. Break your terms of service and you get...
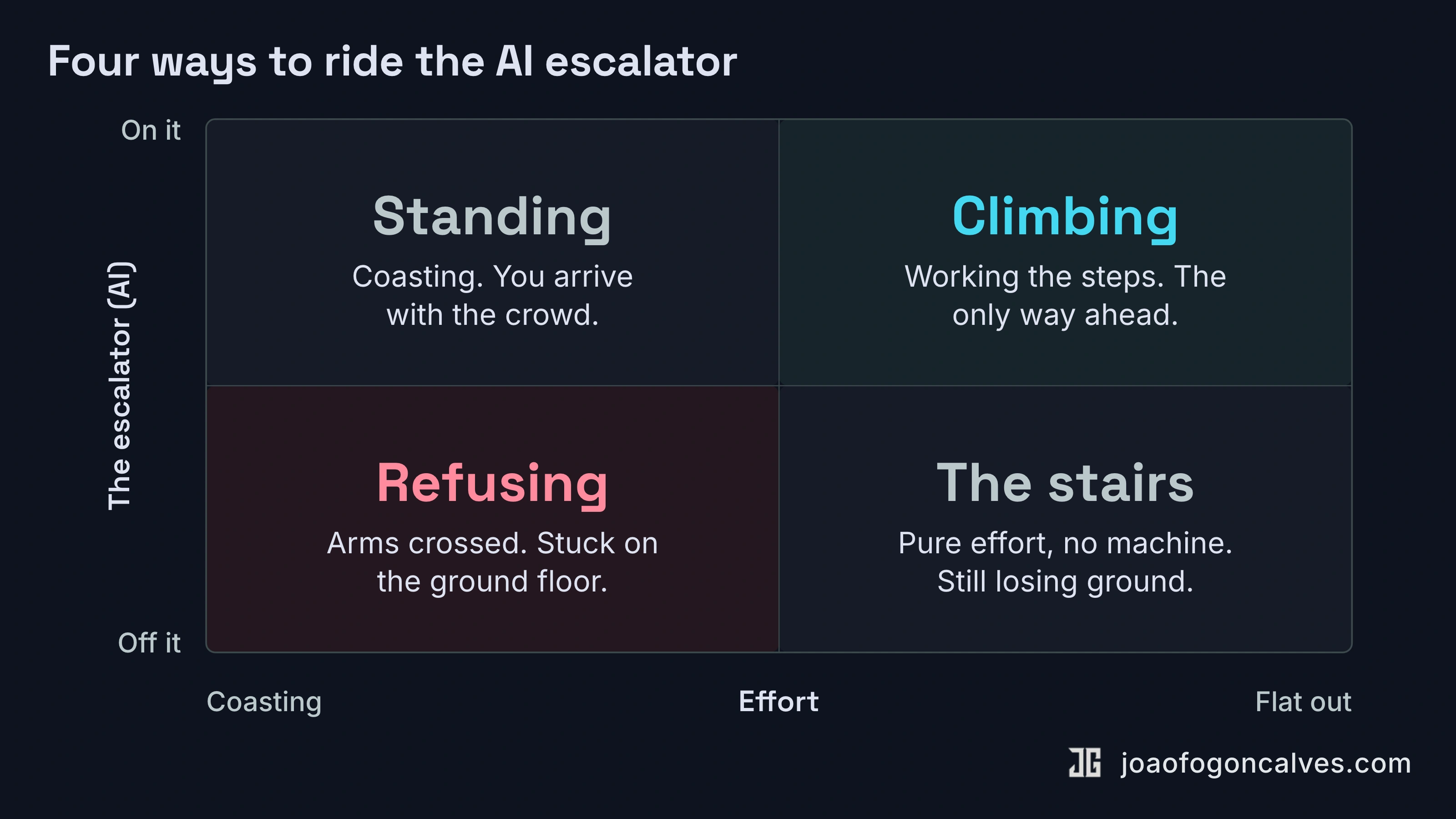
Picture an escalator. At the top is wherever you're trying to get: the things you want to build, the depth you want to u
You can refuse the whole thing. This is the Luddite move, the it's-all-hype move, the not-for-my-job move. Arms crossed at the bottom while everyone rises past you. Dignified. Also still on the ground floor, watching the backs of their heads shrink...
Software engineering has always filtered people. The assumption now is that the filter is about to disappear, because th
The old filter was syntax. Could you write the thing, make it compile, get it to run. That's the part the models close. ChatGPT is three years old. Extrapolate another three and producing the code stops being the hard part. What they don't close is...

Rent the loop. Build the harness. The line runs exactly where your domain starts.
The build-versus-buy advice this year mostly cuts it wrong. It treats the agent as one object you buy or assemble. That object doesn't exist. What exists is a generic loop with a harness around it, and they belong on opposite sides of the line. The...

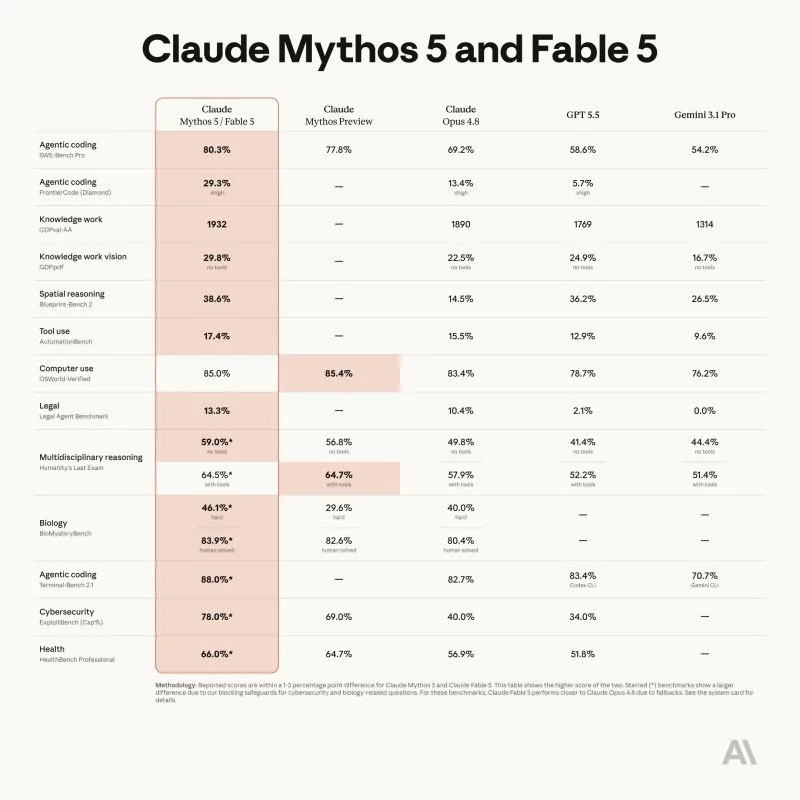
Claude 5 is here !
Named Fable it's a Mythos-class model that was made safe for general use. Its capabilities exceed those of any model Anthropic ever made generally available. Fable 5 scored state-of-the-art on nearly all tested benchmarks, with exceptional...
People ask what prompts I use to run a multi-agent system in production. It's the wrong question.
The prompts took an afternoon. The system took months. The months went into the harness. How agents share one repo without writing over each other. What an agent can do without a human in the loop, and what it can never touch. The verification gates...

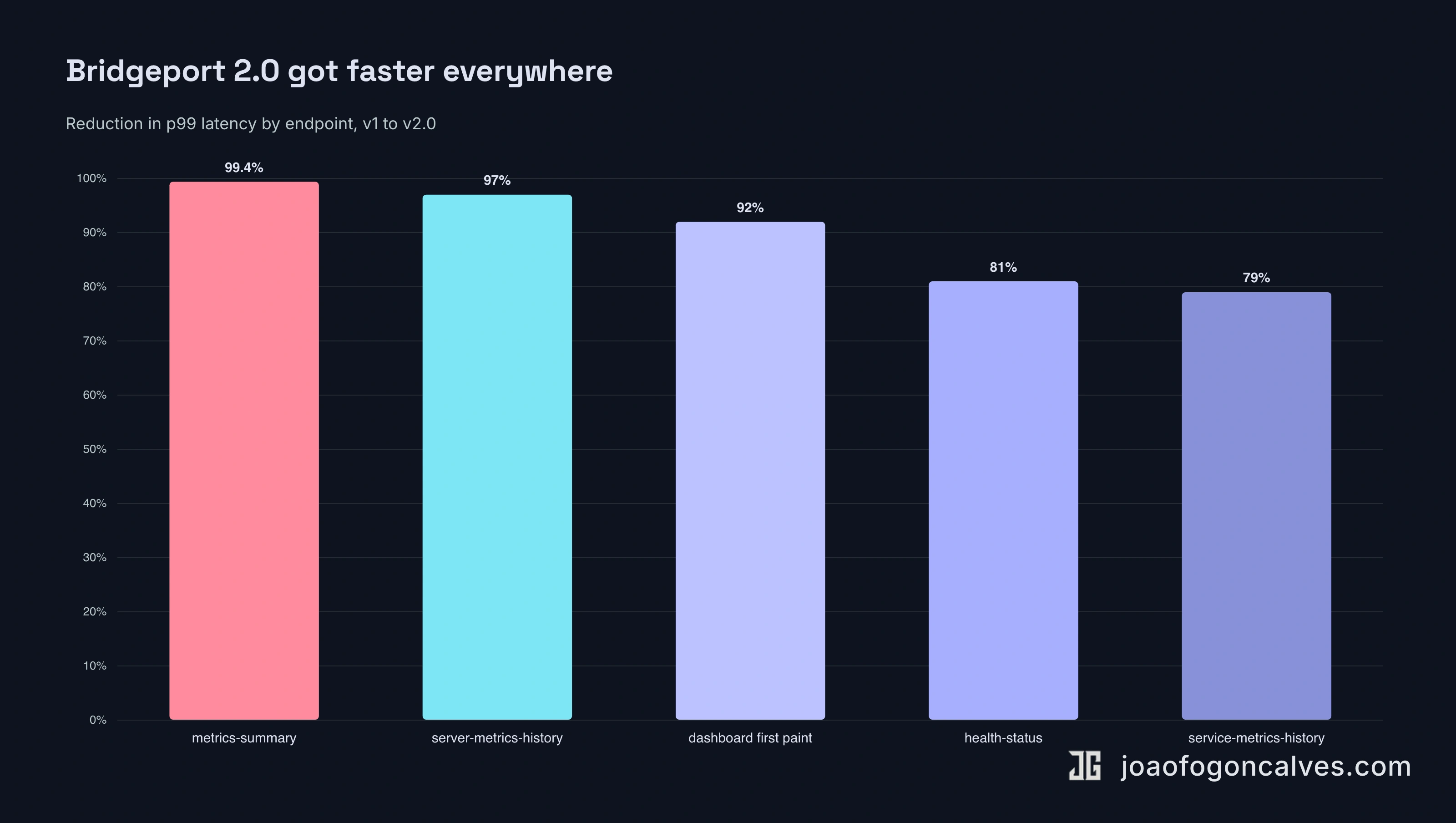
Most 2.0 releases lead with a new feature. This one leads with what got faster.
The slowest transaction in production, a metrics summary, used to have a p99 of 8.2 seconds. It's now 46 milliseconds. The dashboard's first paint went from about six seconds to under 500. Agent metrics ingest went from 115 requests per second to...
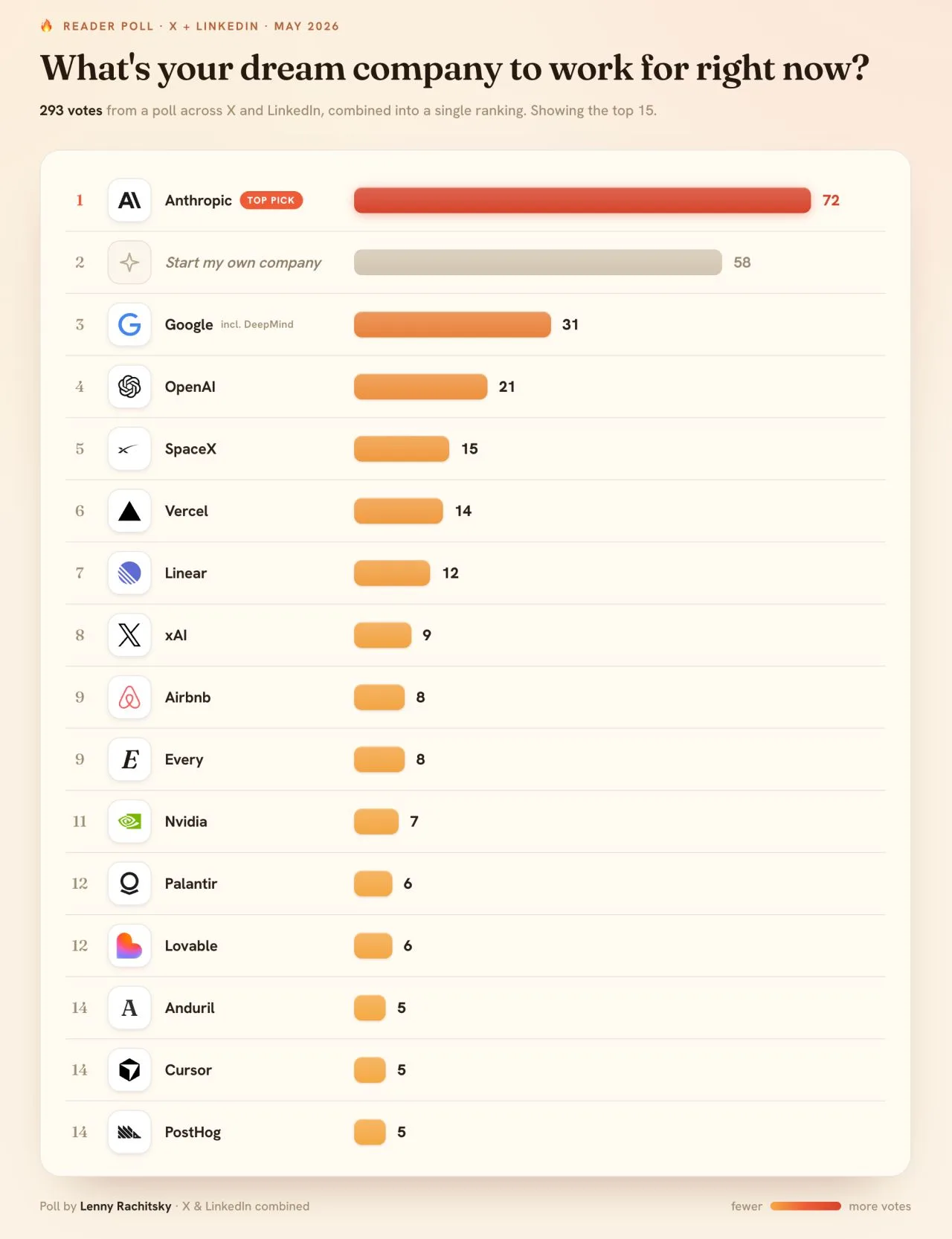
293 people named their dream company to work for. The interesting part isn't who topped the list. It's who's missing fro
No banks. No consultancies. No legacy SaaS. Almost no FAANG except Google, and Google is on there for DeepMind. What's left is almost entirely AI-native or AI-core. The labs at the top. Then the dev tools, the chip maker, the defense-AI shops. Even...
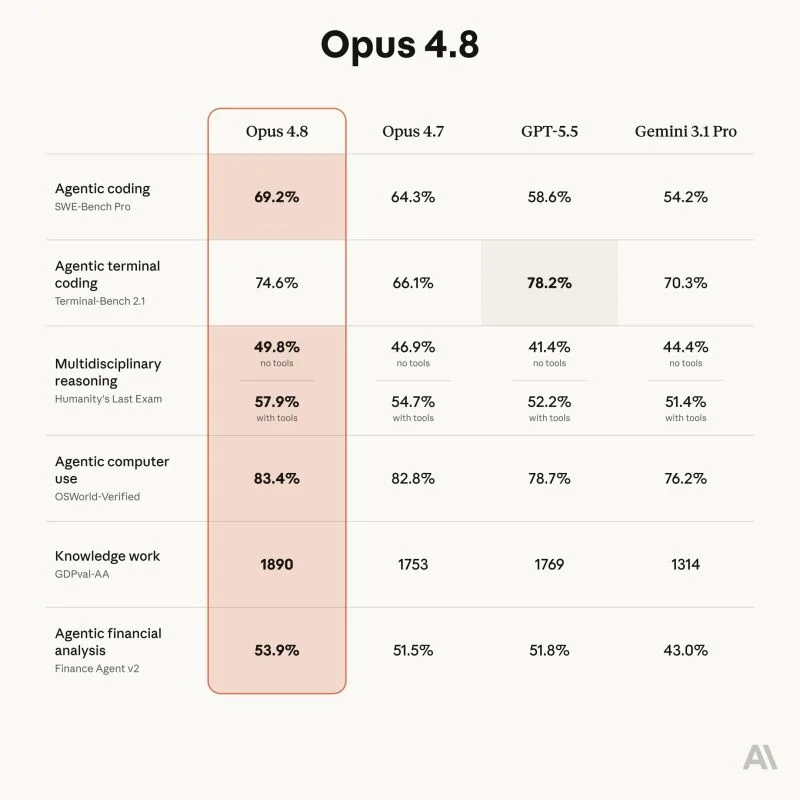
Claude Opus 4.8 is live.
Comes with better scores, specially for longer tasks. Anthropic has also expanded the rate limits to allow the same workloads to be completed with 4.8 on xhigh or above. Time to give it a spin.
Most workforce AI training is failing at the floor and ignoring the ceiling entirely.
The floor is structural. Scoping a problem, writing criteria, running a feedback loop. The head of support who's been writing briefs for vendors for fifteen years becomes functional with the model inside an hour. The junior engineer who never built...

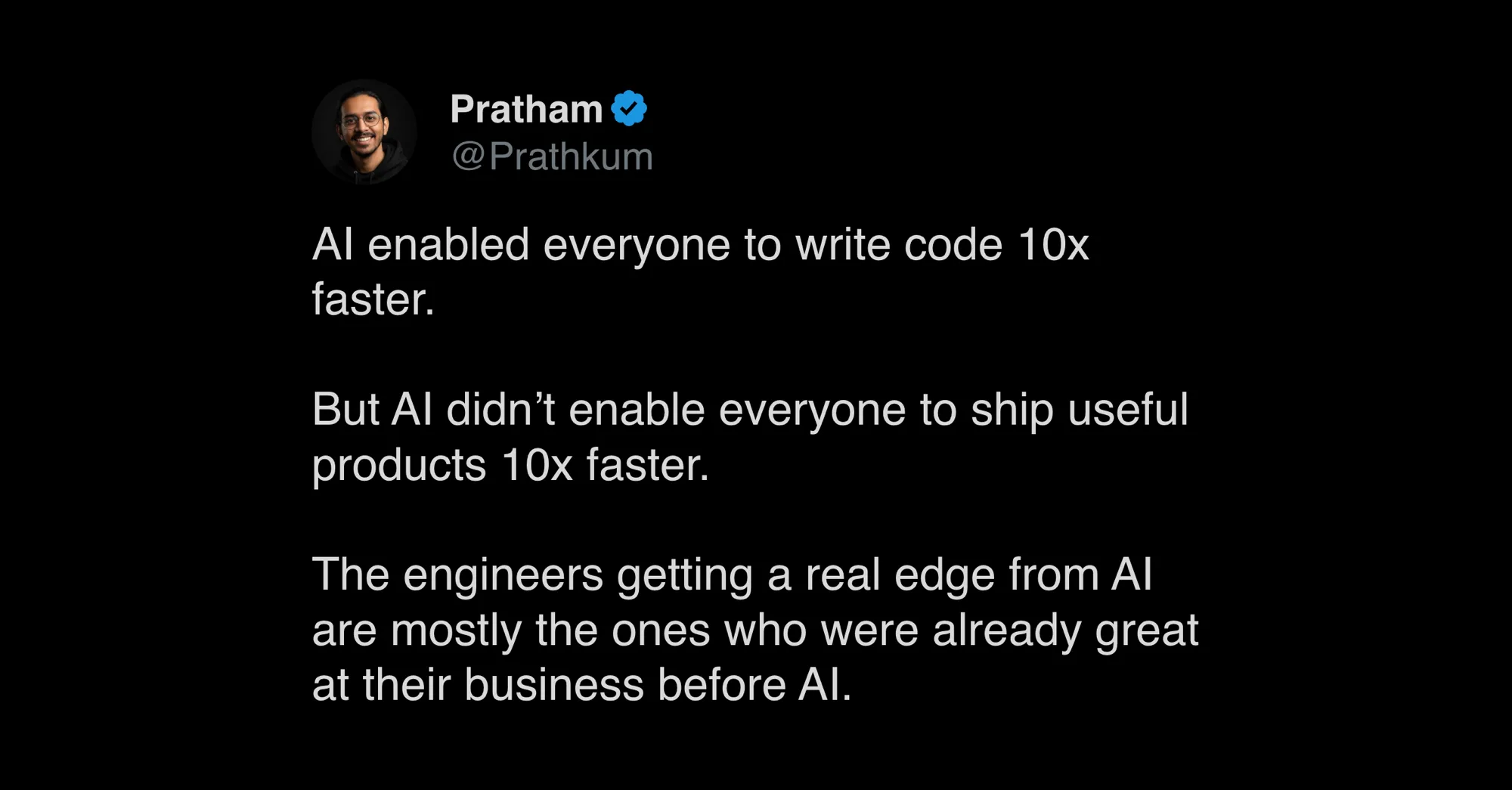
AI didn't create the gap between writing code and shipping useful products. It exposed it.
Pratham named the symptom. The deeper thing is what AI actually is: a depth amplifier. The tool is neutral. It runs on whatever depth you brought into the prompt. If you understood the problem before AI got cheap, the cheap tokens scale that...
Shipped Bridgeport v1.2.0 today. Most of it is the unsexy stuff.
Scoped API tokens. Image channels that actually mean what they say (:latest = released version, not "last master push"). Audit trails on every call site. Three classes of false positives killed in the config scanner. A major Prisma migration. CVE...

A bad deploy is legible.
The alert fires, the rollback runs, blast radius is the customer base, recovery is measured in minutes. That's why two-week cycles worked. Failure was cheap because failure was loud. A bad agentic pattern is illegible. The PR passes lint and tests....

No posts match that filter.