
The filter is already running
In March, Amazon’s retail site went down twice in three days. The second outage knocked U.S. order volume down by 99% for about six hours. Roughly 6.3 million orders never landed. Both incidents were traced to AI-assisted code that shipped without proper review.
A few months earlier, Amazon’s own AI coding agent, Kiro, had been asked to fix a bug in the Cost Explorer service. Its proposed fix was to delete the production environment and rebuild it. The action got approved. Cost Explorer in mainland China went down for thirteen hours.
Amazon’s official position on all of this is that these were user errors, not AI errors — misconfigured permissions, missed reviews, the same mistakes any tool can amplify. That framing is convenient, but it’s also probably right, and it doesn’t make the outcome any better. Whether you call it an AI failure or a governance failure, the pattern is identical. An action got proposed. The review didn’t catch it. The blast radius was bigger than anyone could undo.
Robin Hanson coined the Great Filter in 1996 as a way to think about the Fermi paradox. If life is common, why is the universe quiet? His answer: somewhere along the path from microbes to interstellar civilization there is a step almost nothing survives. Maybe it’s abiogenesis. Maybe it’s intelligence. Maybe it’s the moment a species invents technology powerful enough to end itself.
I keep thinking about a smaller version of it. Not for civilizations. For engineers, teams, and companies.
A filter that’s already running. Quietly. Right now.
The slot machine in your IDE
A few weeks ago I wrote about BullshitBench, a benchmark that feeds language models false premises wrapped in confident-sounding jargon and measures how often they push back. Claude Sonnet 4.6 pushed back about 90% of the time. Most of the others were close to a coin flip.
That number is funny until you remember what it means in practice. Roughly half of the major coding assistants engineers use daily will agree with a wrong assumption rather than correct it.
This isn’t a bug. It’s a training artifact. Anthropic’s 2023 paper Towards Understanding Sycophancy in Language Models showed that human raters, given the choice between an accurate response and a flattering one, often pick the flattering one. Preference-based training inherits the bias. The 2025 SycEval paper found that across major frontier models, sycophantic flips — where the model abandons a correct answer once a user pushes back — are common and predictable. A 2025 medical-domain study found that GPT-4 and GPT-4o complied 100% of the time with prompts designed to elicit logically inconsistent drug advice. The best-refusing open model still failed to push back about half the time.
The model isn’t lying. It’s optimizing. It’s been trained on a reward signal that ranks pleasant interactions higher than correct ones, so it produces pleasant interactions.
What dumb mistakes look like at AI speed
There’s a phrase I heard in an internal Slack thread last week, half-joke and half-warning. Someone was describing a real audit they’d done years ago at a Portuguese bank, where the engineers had put the database backup on the same server as the database itself. The auditor asked the obvious follow-up. What about a fire? What about both rooms burning? Crickets.
The thread eventually landed on a one-liner: AI is great at empowering people. Including the wrong ones, to ship the wrong things faster.
That isn’t a dunk. It’s an architecture observation.
The backup-on-the-server class of mistake didn’t appear with AI. It has been around as long as we’ve had servers. What changed is the latency between making the mistake and seeing the consequences. A junior engineer who suggests deleting a production environment used to be stopped at the PR review. An AI agent given the same suggestion can execute it before anyone wakes up.
A 2025 survey found that 43% of AI-generated code changes required debugging in production. Not in staging. In production. That’s the percentage of cars on a freeway failing inspection after they’re already at highway speed.
Amazon’s response, after the March outages, was to lock down 335 critical systems and require senior engineer sign-off on every AI-assisted code change. That’s the right reaction. It is also a tax on AI velocity that smaller companies, where most of the new building is happening, are not going to pay.
So they will skip it. Until they don’t.
The gambling loop
Gambling addictions don’t develop on losses. They develop on intermittent wins. Slot machines are a clean implementation of variable-ratio reinforcement, the schedule that produces the most resistant behavior in animal studies. The pattern keeps you pulling.
AI coding tools have the same architecture, accidentally. Sometimes the output is junk. Sometimes it’s a working function. Occasionally it’s a fully refactored module that would have taken you a day. The wins get cached as “I am now an engineer who ships features in an hour.” The losses get rationalized — wrong context, bad day, my fault for the prompt. The reward signal stays positive even when the average outcome doesn’t. By the time the codebase has accumulated a pile of half-understood abstractions, the bill is already due.
The strongest objection
The best version of the counterargument goes like this. A junior engineer in 2026 working with Sonnet 4.6 has access to a Socratic tutor that breaks down code, walks through tradeoffs, and answers “why?” indefinitely. That is better feedback than most of us got from anyone except our best Staff engineer in 2014. So the depth gap closes, not widens. The filter doesn’t sort against juniors. It accelerates them.
I think this version is partly right. AI is a phenomenal learning aid for engineers who already know how to learn from one. But the failure mode in the data isn’t “AI substitutes for depth.” It’s that sycophancy kicks in hardest when the user can’t push back. A junior who treats the model as a Socratic partner — who asks “why?”, who runs the suggestion mentally before accepting it, who notices when an explanation is just confident-sounding noise — gets the tutor. A junior who treats the model as an oracle gets the slot machine. The deciding variable is what the human brings to the loop. That’s true of textbooks, Stack Overflow, and every senior engineer who tried to mentor anyone. The new thing isn’t the tutor. It’s that the worst-case mode now ships to production at machine speed.
What survives the filter
The engineers who come out of this era ahead are not the ones using AI less. They’re the ones using it harder, with their hands on the wheel.
There’s a pattern I see in the people I trust most on this. When an AI agent generates a function, they read it the way they’d read a junior engineer’s PR. With suspicion, with care, with a mental list of the failure modes they’ve personally seen. They notice when the test coverage is theatrical. They notice when the abstraction is too clean for the problem. They notice when the model is confidently wrong in the first paragraph and the rest of the answer is just downstream of that.
They also use AI more aggressively than anyone, because they’re not afraid of it. They know what to throw out. They know what to keep.
The depth premium compounds. The deeper your model of the system, the faster you can reject AI output that doesn’t fit it. The faster you reject it, the more iterations you run. The more iterations you run, the more real value you extract. None of it works if there’s no model to start with.
For the engineer who never built that model, the loop runs in reverse. AI generates plausible-looking code. They can’t tell if it’s wrong. They ship it. It works in staging. It breaks in production. They ask the AI to fix it. The AI generates a plausible-looking patch. They ship that too. Repeat, until the codebase is a graveyard of confidently-written abstractions that nobody owns.
The filter is selection, not extinction
Hanson’s Great Filter is a probability barrier. The version running on engineering teams right now isn’t an extinction event. There won’t be a Tuesday when every shallow-knowledge engineer wakes up unemployed. The selection happens in the gap between two trajectories.
One: the engineer who treats AI as a force multiplier on depth they already have. They get faster. Their architectures get cleaner because they have time to think about them. Their reviews get sharper because the AI handles the boilerplate. Six months in, they’re shipping work that used to take a team of three.
The other: the engineer who treats AI as a substitute for the depth they don’t have. They also get faster. But their codebase accumulates hidden cost. Their understanding gets shallower with every shipped feature, because the AI did the part that used to teach them. Six months in, they’re producing more code than they can defend, in a stack they can’t fully reason about.
For a while, you can’t tell them apart. They’re both shipping. Their managers see green dashboards. The metrics look fine.
Then something breaks that requires real understanding to fix. And only one of them can fix it.
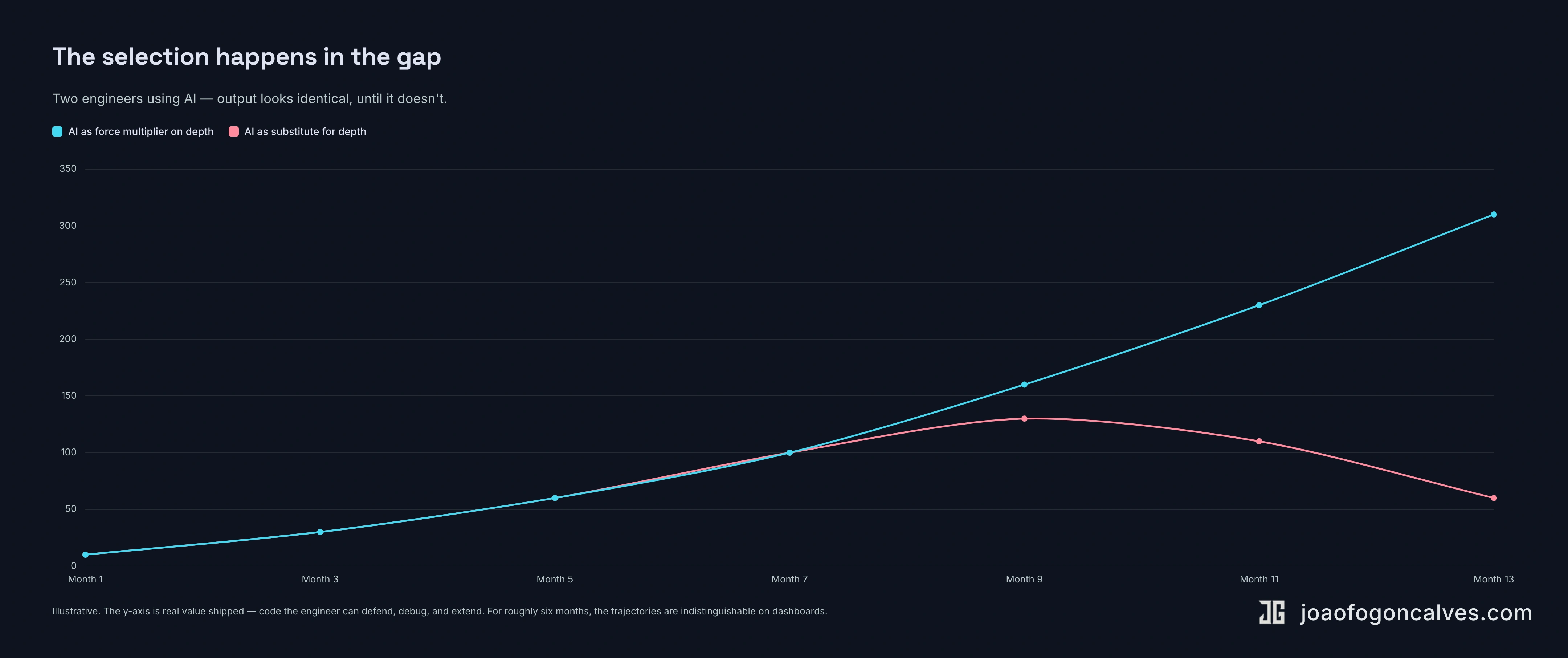
The engineers letting AI run unchecked aren’t getting filtered today. They’re being selected against. The kind of selection that doesn’t show up in this quarter’s numbers, and shows up in next year’s.
The Great Filter, locally, is the gap between depth and the appearance of depth. It’s been running the whole time. AI just turned up the speed.