
I sat through one of these last quarter. Over twenty people on a video call (the “conference room” was a Zoom grid), a slide deck with the OpenAI logo cropped slightly wrong, a vendor walking everyone through a prompt template for writing emails. Subject: marketing campaign for Q3. Tone: professional, friendly. Paste. Hit return. ChatGPT produced six bullet points. A few thumbs-ups landed in the chat. The vendor moved to slide forty-one.
Everyone left feeling productive.
The training was real, the slides were fine, the prompt template worked. None of it would have taught anyone how to use AI on anything that compounds. The visible surface is the part that sells as a course. The skill is one layer down.
01 — The visible surface
There is a default shape to AI literacy training in 2026. Show the demo. Hand out a prompt template. Have people paste it into ChatGPT and rewrite an email. Maybe a tool tour at the end: here is Claude, here is Gemini, here is your Microsoft Copilot license.
The format is legible. It demos well. It fits a slide deck. You can sell it as a half-day course and book it through procurement.
To be fair: the email-rewriter does work. The summarize-this-meeting prompt does work. Lifting the median knowledge worker on small, well-bounded tasks is a real use case, and the prompt template is roughly the right shape of training for it. The problem is what gets confused with that. The same procurement line item is being sold to engineering leaders, product orgs, and operations heads as if it would do the work that decides whether the company has an AI advantage. It will not. That work is different.
MIT’s 2026 NANDA report put a sharp number on the gap: 95% of enterprise generative AI pilots produced no measurable P&L impact inside six months. The methodology has been contested, and the headline is harsher than the underlying numbers warrant, but even the conservative reads agree that only a third of enterprise AI pilots reach production. The model is not the variable that broke those pilots. The system around the model was.
A prompt template gets you a generic output on a small task. Working with AI on anything that compounds looks different. It looks like breaking a problem into pieces small enough to fail at visibly, knowing what good looks like before the model writes anything, telling it what is wrong with what it gave you, and iterating until it isn’t. None of that is in the slide deck. All of it is now the actual work.
The prompt is the artifact. The skill is upstream.
02 — The system the model operates inside
What people are reaching for when they say “prompting” is, almost always, a different and older skill. It has five rough parts.
Scope. You name the problem precisely enough that a stranger could tell whether the output solves it. Not “help me with the deployment pipeline.” Something like: walk me through each step from commit to production, flag the steps that take longest, suggest where we could parallelize. The first one is a wish. The second one is a question.
Decomposition. You break the work into chunks small enough that the failure modes are visible. The model is going to fail. Your job is to design the work so that the failures are caught, not absorbed. A single mega-prompt that says “build me a marketing site” hides every decision the model is making. Six small prompts each producing a verifiable artifact does not.
Criteria. You write down what good looks like before the model writes anything. In measurable terms. Three bullet points. Two paragraphs of source material cited. No hedging language. No marketing-speak. The rubric is what an evaluation harness checks against — without it, you have no way to know whether a run regressed. If you can’t write the rubric, you don’t know what you want, and the model is going to make a confident guess on your behalf.
Feedback loops. You have a way to tell the next iteration what the last one got wrong. This is the part the templates skip entirely. It is also the part that compounds.
Making the implicit explicit. Every time you correct the model in your head and don’t write the correction down, you are training nobody and nothing. Models are stateless and non-deterministic. They do not learn between conversations the way a contractor learns between engagements. The system around them has to carry what a person would have carried in their head. Put the correction in a system prompt, a skill file, a project doc, anywhere the next run will read it. That is what “system” means in this article. Not orchestration framework. The set of inputs the next run sees.
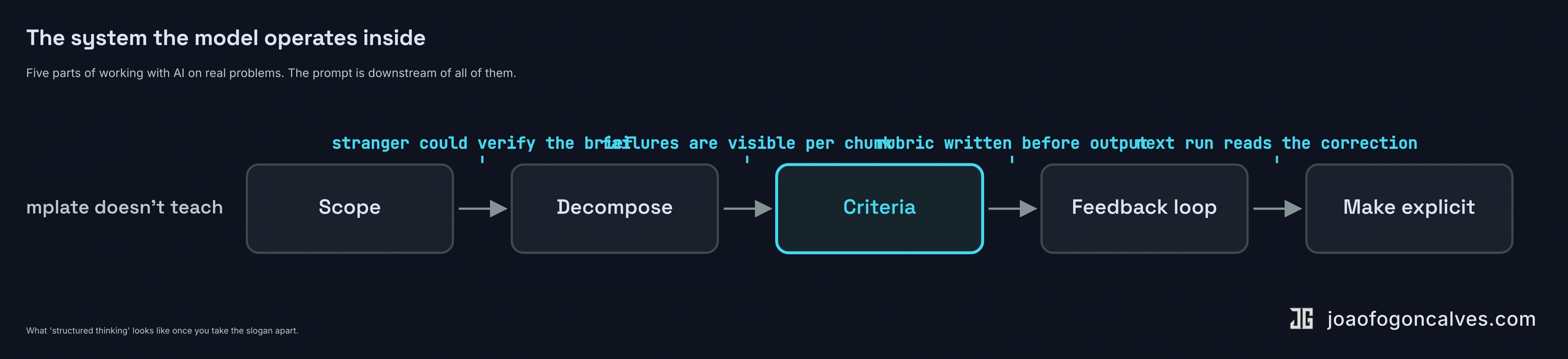
Five things. None of them are about the model. All of them are about the design around the model.
This is not new in shape. Scoping, criteria, and structured feedback are familiar from any well-run engineering organization. What is new is what carries the learning. A junior engineer remembers a code review three weeks later. A model does not. Skill files exist precisely because nothing else does the carrying.
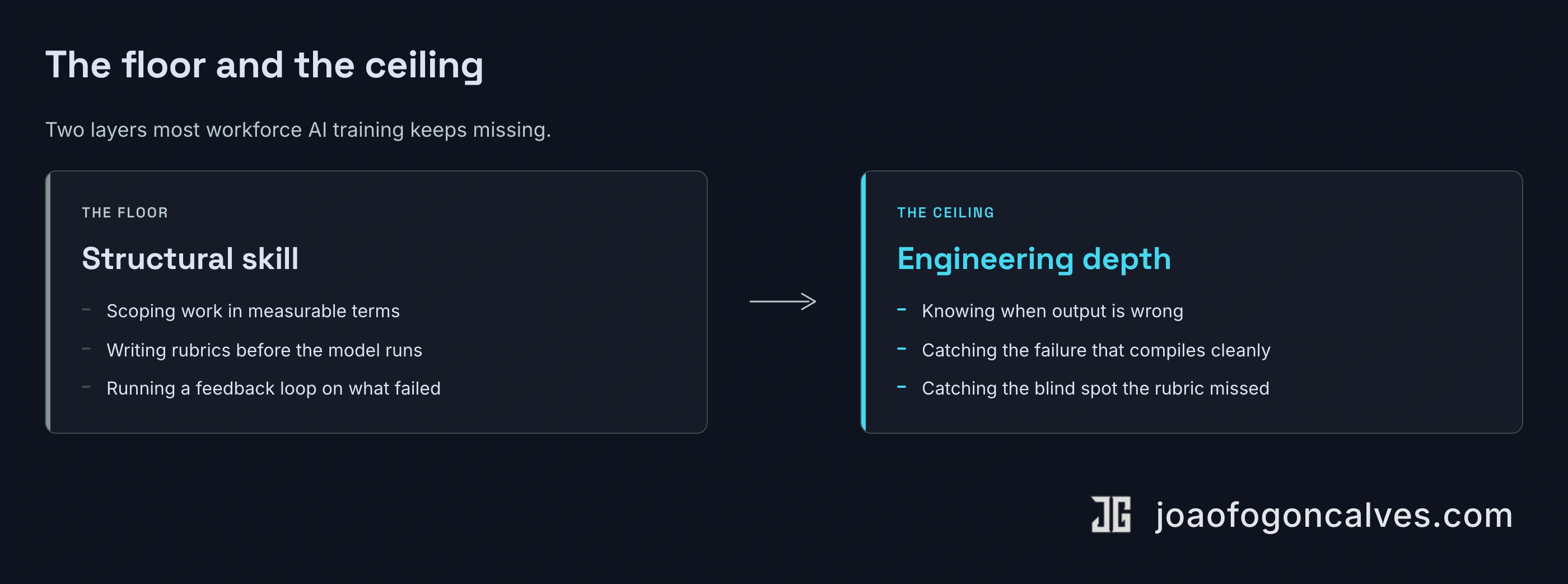
03 — The floor and the ceiling
I have been running prompting sessions for over 6 months. The pattern is consistent.
The floor is structural. People who already know how to describe work in measurable, scoped, criteria-bearing terms become functional with almost any model inside an hour. The transferable competence is mostly older than the technology.
A head of support I worked with started a session with “I want to get more insights out of HubSpot.” Fifteen minutes later, with two questions from me, she had written: pull every support ticket from the last 90 days, group them by the product surface the customer was asking about, count tickets per surface, and surface the three themes with the steepest volume growth over the period. She did not learn a prompt. She remembered how to write a brief. She has been writing briefs for vendors and consultants her entire career. The model is just the newest contractor.
The ceiling is something else. It is engineering depth — the ability to look at output and know whether it is wrong. Structural skill gets you a working interaction. Depth is what catches the failure that compiles cleanly, passes the rubric you wrote, and ships your blind spot at scale.
I wrote about this in AI as the Great Filter. The short version: engineering depth used to be a nice-to-have. Now it is the variable that decides who survives the next layer. The engineers who already had the muscle — architecture decisions, code review, design docs, naming a failure mode before someone hits it — compound. The ones who treated cheap AI as a substitute for that muscle ship fluently-broken code at scale.
The trap on the engineering side is the interesting one. Technical literacy looks like depth and is often the opposite. Knowing the stack makes it tempting to skip system design and just write the code yourself. AI made that trap deeper, not shallower. The engineer who used to write a function in 30 minutes now writes it in 90 seconds with Claude. The gap from spec to output is almost entirely verification. If you can’t articulate what good looks like before the model produces it, your verification reduces to “looks right.” That ships your blind spots faster, with more confidence, in larger volume.
A two-hour prompt-engineering workshop teaches the model interface. It teaches nothing about how to know whether the output is wrong. The engineer who could already eyeball a design and say “this won’t work under load” gets faster. The engineer who could not gets a paste-bin of plausible code and a working keyboard.
The floor is structural. The ceiling is engineering depth. Most workforce AI training is failing at the floor and ignoring the ceiling entirely.
04 — aiBerto, the receipt
We have an AI engineering agent at BRIDGE IN. His name is aiBerto. He lives in our Slack, picks the next issue off our project board every couple of hours, opens a PR, runs CI, fixes failing checks, asks for review when he’s stuck. Last month he merged 30 PRs autonomously (zero human commits on his branches), opened 107 GitHub issues, resolved 104, and handled 81 Slack interactions.
He didn’t get smarter last month. The underlying model didn’t change.
He got 40 skill patches.

Forty sentences, written by humans who watched him fail at something specific and figured out what he should have known. Every patch sits in a markdown file in our repo. The next time aiBerto runs the relevant skill, the file gets prepended into his context window. The failure mode stops happening.
A recent one: aiBerto’s /build skill was occasionally merging a PR without explicitly linking it back to the originating GitHub issue. The PR closed the issue via a keyword in the body, which was enough for GitHub but not enough for our project board. A teammate noticed the same failure twice, patched the skill with a one-line “guarantee the PR-issue link before merging” step, and the failure mode disappeared. He did not retrain anything. He wrote a sentence. The sentence is in the repo.
None of those forty sentences are prompts in the popular sense. They are pieces of system. Before merging, link the issue. When CI fails on lint, run the linter locally first. When triaging Sentry, dedupe by stack hash before opening tickets. Each one is a piece of organizational knowledge made explicit, written down, and put on the model’s read path.
The honest question an engineering leader asks here is the regression question: how do you know patching one failure didn’t break three others? Answer: an eval suite that runs the agent against a set of historical issues and PRs before any skill change merges. It catches local regression. It does not catch the harder problem, which is architectural drift across many small clean diffs — the fifth PR through the same area of code surfacing a pattern the previous four missed. The eval handles the failures we already know to look for. The drift is the part we are still writing the system around.
The model is the same. The system around it got better. The agent’s effective intelligence rose because the people closest to each kind of failure added the missing piece of context. That is system design. It is also what AI literacy looks like at scale.
The longer version of this story has the metrics. The shape that matters is this one: forty sentences moved more output than any prompt-template handout ever could.
05 — What a real curriculum looks like
If I were running an honest AI literacy program for an engineering organization, the agenda would look almost nothing like the one I sat through.
Pick a real problem the team actually has. Not a sample case study, not a “draft this email” exercise. A real Sentry bucket. A slow code review queue. An incident post-mortem nobody has written yet.
Before anyone opens a model, write down what done looks like. In measurable terms. The same rubric you would put on a sprint planning ticket. Three bullets. Pass criteria. A test you could run.
Break the problem into the smallest unit the AI can fail at visibly. If the unit is too big to verify, it is too big to delegate. Split it. The unit looks a lot like a small PR.
Write the evaluation rubric yourself. Not the one the model suggests. The model will suggest a flattering rubric. That is what models are tuned to do.
When the output is wrong, write the missing sentence the next run would need to read in order to not be wrong in the same way. Put it in version control. Now you have a system. Now you also have a regression target — the next change runs against the same sentence and the team sees whether it still holds.
Do this for four weeks. The deliverable is not a slide deck. It is a markdown directory of sentences a team’s worth of people wrote because they watched something fail and figured out what it should have known. That directory compounds. The slide deck does not.
The engineering-org version of this argument is adjacent. Bolting Copilot onto a workflow is not AI-first. Bolting prompt templates onto a workforce is not AI-literate. Both confuse the artifact for the work.
Back to the call
The twenty-plus people on that call are not at fault. The vendor is not, mostly, dishonest. The slide deck and the prompt template are not wrong for what they’re trying to do.
The honest version of the same training would have looked almost nothing like it. The vendor would have opened the team’s actual bug tracker. Pulled the next issue. Asked someone what done looked like, in measurable terms, before anyone touched a model. Made them write the rubric. Run the model. Watched it fail at something specific. Asked someone else what the missing sentence was. Committed the sentence to the repo. Run it again. Saved the rubric, the failure, and the sentence as the artifact of the session.
The deliverable would have been a markdown file the team kept, not a slide deck the team forgot.
The skill is older than the model. The model is just the latest reason to teach it.